| Efficient-NeRF2NeRF Streamlining Text-Driven 3D Editing with Multiview Correspondence-Enhanced Diffusion Models |
|
Liangchen Song1 Liangliang Cao1 Jiatao Gu1 Yifan Jiang12 Junsong Yuan3 Hao Tang1 1 Apple 2 UT Austin 3 University at Buffalo |
|
arXiv
Code (unofficial)
Unofficial code but well aligned with our results
|
Video
Overview
| TLDR: Applying multiview-consistency regularization to Instruct-Pix2Pix can accelerate the 3D editing process. |
| The advancement of text-driven 3D content editing has been blessed by the progress from 2D generative diffusion models. However, a major obstacle hindering the widespread adoption of 3D content editing is its time-intensive processing. This challenge arises from the iterative and refining steps required to achieve consistent 3D outputs from 2D image-based generative models. Recent state-of-the-art methods typically require optimization time ranging from tens of minutes to several hours in order to edit a 3D scene using a single GPU. In this work, we propose that by incorporating correspondence regularization into diffusion models, the process of 3D editing can be significantly accelerated. This approach is inspired by the notion that the estimated samples during diffusion should be multiview-consistent during the diffusion generation process. By leveraging these multiview-consistency, we can edit 3D contents with a much faster speed. In most scenarios, our proposed technique brings a 10$\times$ speed-up compared to the baseline method and completes the editing of a 3D scene in 2 minutes with comparable quality. |
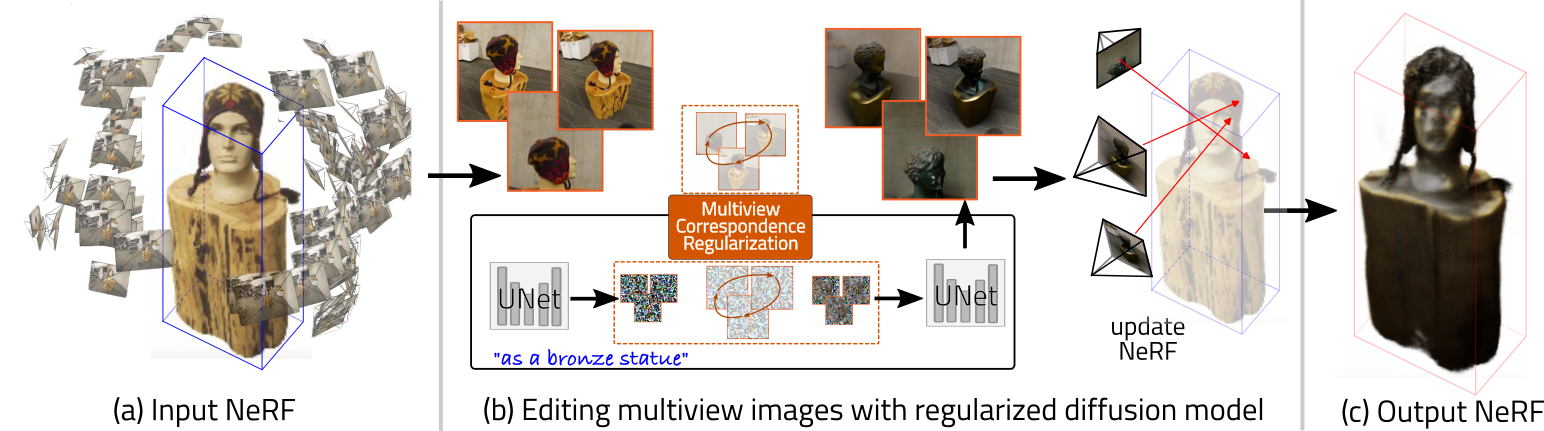 |
| We regularize that the output obtained during the denoising process of diffusion aligns with the input multiview images in terms of multiview correspondence. The multiview correspondence is applied on the estimated latents during denoising, as shown below. |
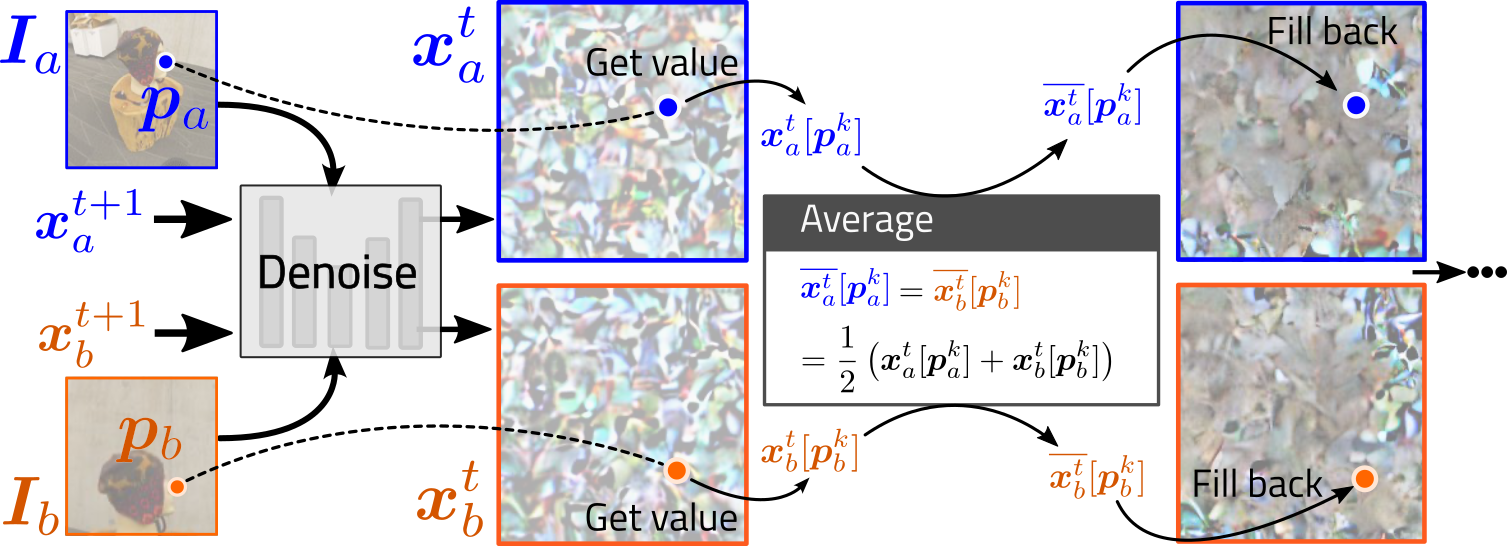 |
| In the above figure, ${I}_a$ and ${I}_b$ are input views with correspondence pair $({p}_a,{p}_b)$. ${x}_a^t$ and ${x}_b^t$ are the samples at time $t$. |
Related Works
| 👍 Instruct-NeRF2NeRF: The method that our model is based on. If you haven't read this, please read it first. |
| 👍 SDS based editing methods: Vox-E, FocalDreamer, AvatarStudio, and DreamEditor. |
| 👍 Gaussian Splatting based efficient editing methods: GaussianEditor from Huawei, and GaussianEditor from NTU. |
| 👉 More related works, like CLIP-based methods (NeRF-Art), can be found in our paper. |
Citation
@article{song2023efficient,
title={Efficient-NeRF2NeRF: Streamlining Text-Driven 3D Editing
with Multiview Correspondence-Enhanced Diffusion Models},
author={Liangchen Song and Liangliang Cao and Jiatao Gu and Yifan Jiang and Junsong Yuan and Hao Tang},
journal={arXiv preprint arXiv:2312.08563},
year={2023}
}